Paper Replication Lab
In-progressA paper-to-code collection of foundational ML implementations in PyTorch, covering autoencoders, LeNet, AlexNet, LSTM, and a LLaMA-style language model with training and inference utilities.
Role
Model Implementer & Research Engineer
Timeline
Ongoing
Team
Solo
Technologies
Key Metrics
Key Challenges
- •Keeping each implementation close enough to the paper while still readable as learning code
- •Covering different architecture families without turning the repository into disconnected notebooks
- •Separating reusable model code, training scripts, data utilities, and inference paths in the LLaMA module
Key Learnings
- •How representation learning, convolution, recurrence, and transformer blocks differ at the implementation level
- •Why faithful paper replication needs both architecture code and reproducible training scaffolding
- •How to document models so they are useful as study artifacts, not just runnable scripts
Paper Replication Lab
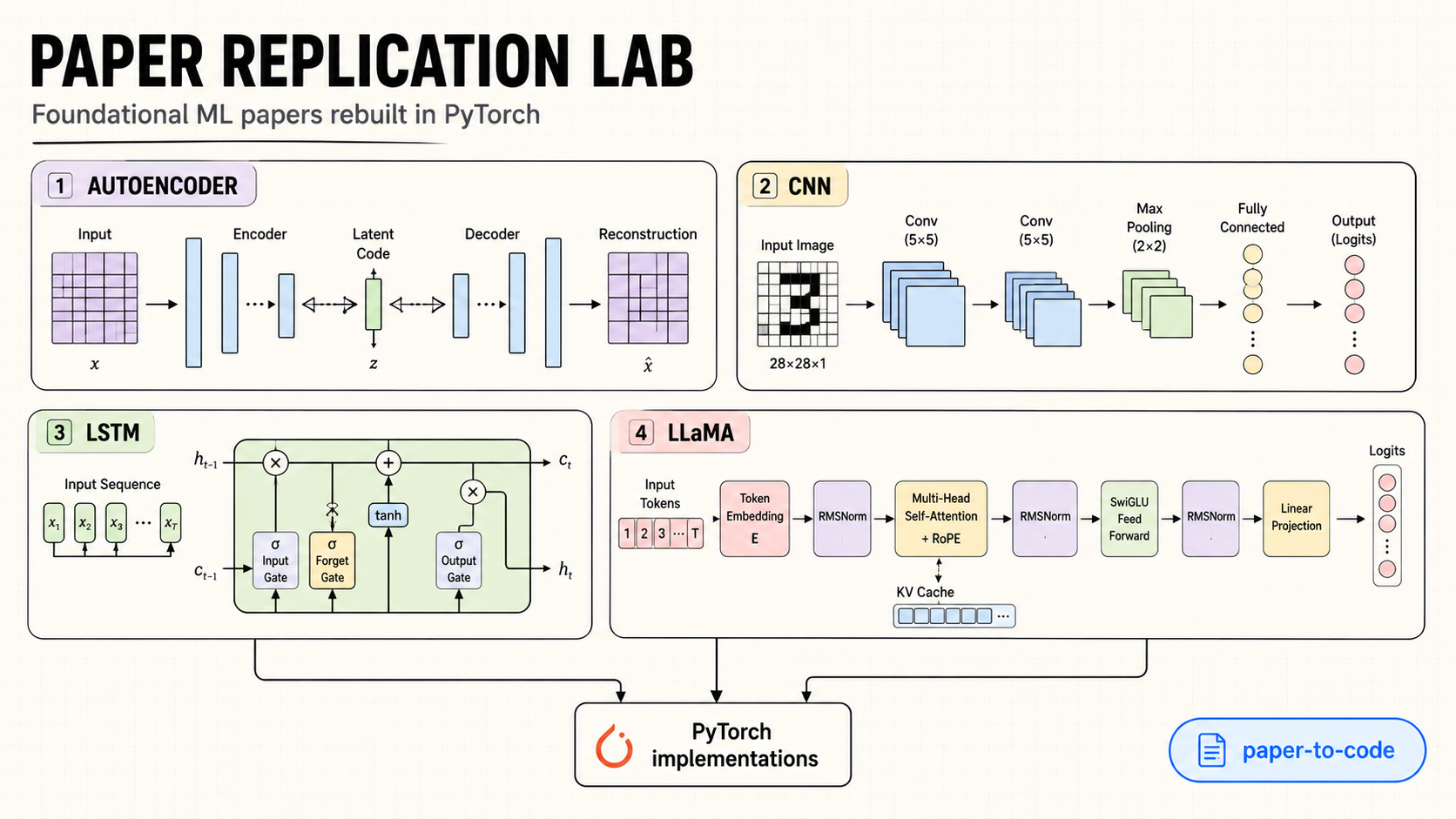
Paper Replication Lab is a hands-on repository for translating foundational machine learning papers into working PyTorch implementations. Instead of treating papers as references on the side, the repo uses them as the primary spec: read the architecture, reproduce the important blocks, train the model, and document what the implementation teaches.
The collection spans both notebook-based study artifacts and a more modular language-model implementation. That makes it useful as a compact research-practice proof: it shows the ability to move from architecture diagrams and paper descriptions into executable model code.
What It Covers
- Autoencoders for learning compressed representations through an encoder, latent bottleneck, and reconstruction decoder.
- LeNet and AlexNet for understanding the evolution of convolutional neural networks from small handwritten-digit classifiers to deeper visual feature extractors.
- LSTM for sequence modeling with gated recurrent memory, making the difference between plain recurrence and controlled state updates concrete.
- LLaMA-style language model for transformer language-model architecture, with separated model definition, training, advanced training, inference, data utilities, and configuration.
Repository Architecture
The repo is organized around paper families first, then implementation surfaces inside each family.
Encoder-decoder flow from tokens to output probabilities.
Design Intent
The goal is not to build a production model zoo. It is to make the implementation choices behind major model families legible:
- what the architecture is trying to represent,
- where the important tensors move,
- which blocks are essential to the paper,
- and how training or inference changes once the architecture becomes code.
That is why the repository mixes notebook implementations with a more structured LLaMA module. The notebooks keep learning loops visible, while the LLaMA folder separates model code from training and inference so the implementation reads closer to a real research artifact.
Why It Belongs In Model Lab
Model Lab is for paper-to-code work, research artifacts, and ML implementations that show architecture understanding. Paper Replication Lab fits that track because it collects multiple foundational replications instead of a single model page.
It complements the individual Transformer and LLaMA entries: those pages go deep on one architecture, while this lab shows breadth across representation learning, computer vision, sequence modeling, and transformer language modeling.
Next Improvements
- Add short paper notes above each implementation so the reader sees the original idea before the code.
- Standardize training summaries across notebooks: dataset, loss, optimizer, metric, and expected behavior.
- Add compact architecture diagrams for each family so the repo can be scanned without opening every notebook.
- Convert the LLaMA module into a clearer mini case study with example generation outputs and training tradeoffs.