Attention Is All You Need
CompletedA PyTorch implementation of the original encoder-decoder Transformer architecture for neural machine translation, including multi-head attention, sinusoidal positional encoding, greedy decoding, OPUS Books training, and CER/WER/BLEU evaluation.
Role
Model Implementer & Research Engineer
Timeline
4 weeks
Team
Solo
Technologies
Key Metrics
Key Challenges
- •Implementing encoder-decoder attention without hiding the mechanics behind a high-level library
- •Keeping masking, positional encoding, and autoregressive decoding aligned across training and validation
- •Building a training loop that reports translation metrics instead of only loss
Key Learnings
- •How multi-head attention routes information through independent representation subspaces
- •Why source masks, target masks, and causal masks are separate concerns in sequence transduction
- •How BLEU, CER, and WER expose different failure modes in generated translations
Attention Is All You Need
This is a paper-to-code implementation of the original Transformer architecture from Attention Is All You Need. The project keeps the model mechanics visible: embeddings, sinusoidal positional encoding, multi-head attention, encoder and decoder blocks, masking, projection, training, checkpointing, and translation evaluation.
The implementation is built for neural machine translation rather than generic text generation. The default setup trains on OPUS Books translation pairs, builds source and target tokenizers, and validates with greedy decoding plus CER, WER, and BLEU.
What It Implements
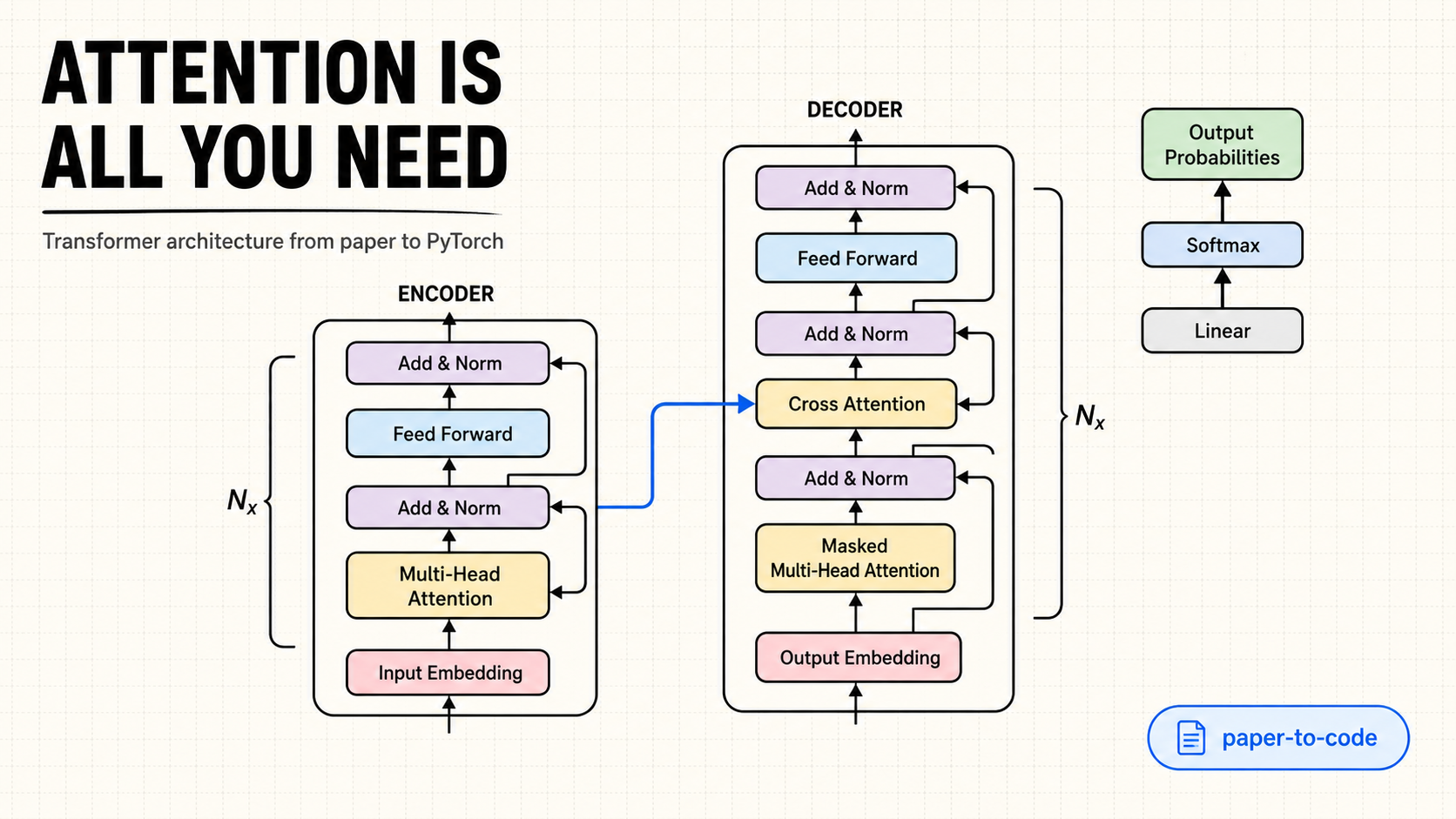
- Encoder-decoder Transformer with stacked encoder and decoder blocks.
- Input embeddings scaled by
sqrt(d_model)so token vectors enter the attention stack at the expected magnitude. - Sinusoidal positional encoding so the model receives token order without recurrence.
- Multi-head attention with query, key, and value projections across multiple representation subspaces.
- Masked decoder self-attention so target tokens cannot attend to future tokens during generation.
- Cross-attention where the decoder attends to encoder context vectors from the source sentence.
- Position-wise feed-forward networks after attention blocks.
- Residual connections and layer normalization around the attention and feed-forward sublayers.
- Projection layer that maps decoder states into target vocabulary logits.
Architecture Flow
The implementation follows the original sequence-to-sequence Transformer path:
Encoder-decoder flow from tokens to output probabilities.
The key design choice is separating the three attention surfaces:
- Encoder self-attention learns relationships across the full source sentence.
- Decoder self-attention learns target-side context while obeying causal masking.
- Decoder cross-attention connects generated target tokens back to source-language meaning.
That split makes the project a useful implementation artifact because it demonstrates the difference between representation building, autoregressive generation, and source-target alignment.
Training Pipeline
The training path is built around Hugging Face datasets and tokenizers:
- Load OPUS Books translation pairs for a source and target language.
- Build or reuse tokenizers for both languages.
- Convert each sentence pair into padded token sequences with special tokens.
- Create source, target, and causal masks.
- Train the Transformer with cross-entropy loss and label smoothing.
- Save checkpoints so training can resume from the latest or a selected epoch.
- Run validation with greedy decoding and log quality metrics.
The default config uses English-to-Italian translation with a sequence length of 350, model dimension 512, 8 attention heads, 6 encoder/decoder layers, dropout 0.1, and feed-forward dimension 2048.
Evaluation
The README exposes more than loss tracking, which is important for translation work:
- CER measures character-level edit distance, useful for morphology and spelling drift.
- WER measures word-level edit distance, useful for phrase-level mistakes.
- BLEU measures n-gram overlap with reference translations, useful for translation fluency and adequacy.
Together these metrics make the model easier to debug than a training loop that only reports validation loss.
Why This Belongs In Model Lab
This model is not just another Transformer tag on a project card. It shows the ability to translate a foundational paper into working PyTorch code with the surrounding training and evaluation system needed to make it usable.
The useful signal here is implementation literacy:
- Understanding how attention blocks compose into an encoder-decoder system.
- Knowing why sequence masks are different for source and target paths.
- Connecting architecture code to dataset preparation and translation metrics.
- Keeping the repository educational without turning it into a black-box library wrapper.
Repository Structure
Attention-is-all-you-need/
├── model.py # Transformer architecture and core components
├── train.py # Training loop, validation, metrics, greedy decoding
├── dataset.py # Bilingual dataset preparation and masks
├── config.py # Hyperparameters and runtime configuration
├── requirements.txt # PyTorch, datasets, tokenizers, metrics, TensorBoard
└── README.mdNext Improvements
- Add beam search decoding for stronger inference quality.
- Add a small qualitative translation gallery.
- Include attention visualization for inspecting source-target alignment.
- Add distributed training support for larger model runs.