LLaMA Implementation
CompletedA PyTorch implementation of the LLaMA (Large Language Model Meta AI) architecture based on the paper LLaMA: Open and Efficient Foundation Language Models by Touvron et al.
Role
Lead Developer & Researcher
Timeline
3 months
Technologies
PyTorchTransformersDeep Learning
Key Metrics
100M
Parameters
Total model parameters for large configuration
2.5x
Training Speed
Speed improvement with mixed precision
40%
Memory Efficiency
Memory reduction with optimizations
Key Challenges
- •Implementing RoPE positional encoding
- •Optimizing memory usage for large models
- •Achieving training stability
Key Learnings
- •Advanced transformer architectures
- •Efficient training techniques
- •Model optimization strategies
LLaMA Implementation
A PyTorch implementation of the LLaMA (Large Language Model Meta AI) architecture based on the paper "LLaMA: Open and Efficient Foundation Language Models" by Touvron et al.
Features
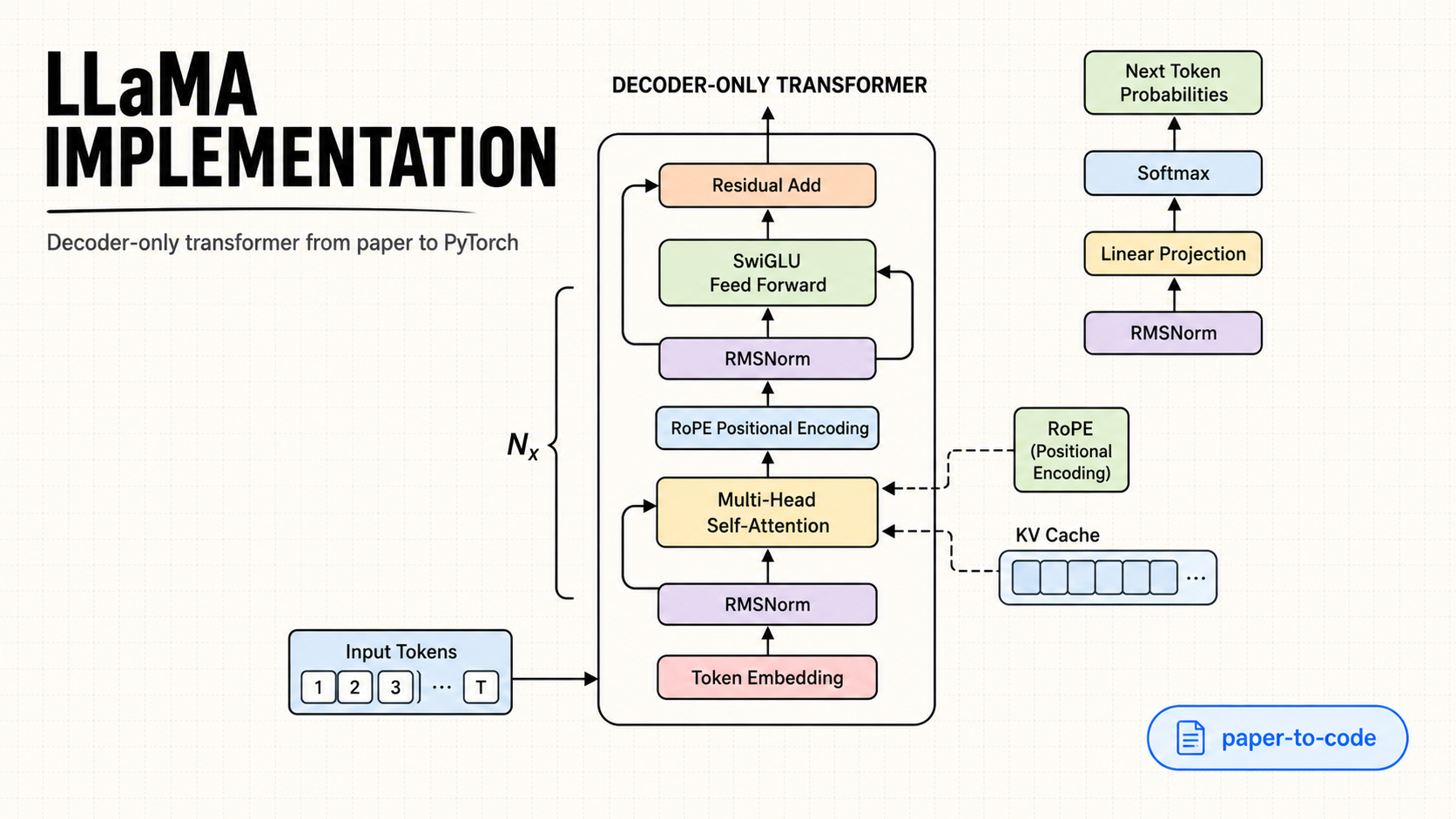
- Complete LLaMA Architecture: Implements the full transformer architecture with RoPE (Rotary Position Embedding)
- Efficient Training: Supports both basic and advanced training with features like:
- Learning rate scheduling
- Gradient clipping
- Mixed precision training
- Model checkpointing
- Early stopping
- Flexible Configuration: Easy-to-use configuration system with different model sizes
- Data Processing: Built-in data utilities for text preprocessing and tokenization
- Inference Support: Complete inference pipeline with text generation
Project Structure
LLAMA/
├── model.py # LLaMA model implementation
├── train.py # Basic training script
├── train_advanced.py # Advanced training with additional features
├── inference.py # Inference and text generation
├── data_utils.py # Data processing utilities
├── config.py # Configuration management
├── requirements.txt # Python dependencies
└── README.md # This file
Installation
- Clone the repository:
git clone <repository-url>
cd LLAMA- Install dependencies:
pip install -r requirements.txt- (Optional) Install additional dependencies for advanced features:
pip install wandb sentencepieceQuick Start
Basic Training
python train.pyAdvanced Training
python train_advanced.py --config medium --use_ampInference
python inference.pyConfiguration
The project uses a flexible configuration system. You can:
-
Use predefined configurations:
small: 256 dim, 4 layers, 4 headsmedium: 512 dim, 8 layers, 8 headslarge: 1024 dim, 16 layers, 16 heads
-
Customize parameters:
from config import TrainingConfig
config = TrainingConfig(
dim=512,
n_layers=8,
batch_size=16,
learning_rate=1e-4
)Model Architecture
The implementation includes:
- RMSNorm: Root Mean Square Layer Normalization
- RoPE: Rotary Position Embedding for positional encoding
- Multi-Head Attention: With grouped query attention (GQA)
- SwiGLU: Swish-Gated Linear Unit activation
- Pre-normalization: Layer normalization before attention and FFN
Training Features
Basic Training (train.py)
- Simple training loop
- Basic checkpointing
- Loss monitoring
Advanced Training (train_advanced.py)
- Learning rate scheduling with warmup and cosine decay
- Gradient clipping
- Mixed precision training (AMP)
- Advanced logging with wandb support
- Model checkpointing with best model saving
- Early stopping
- Comprehensive metrics tracking
Data Requirements
The model expects text data in the following format:
- Plain text files
- UTF-8 encoding
- The training script will automatically download the TinyShakespeare dataset if no data is provided
Usage Examples
Training a Small Model
python train_advanced.py --config small --batch_size 32 --max_iters 1000Training with Mixed Precision
python train_advanced.py --config medium --use_ampCustom Configuration
from config import TrainingConfig, AdvancedTrainer
config = TrainingConfig(
dim=256,
n_layers=6,
n_heads=8,
batch_size=16,
learning_rate=2e-4,
max_iters=2000
)
trainer = AdvancedTrainer(config)
trainer.train()Model Sizes
| Configuration | Dim | Layers | Heads | Parameters (approx) |
|---|---|---|---|---|
| Small | 256 | 4 | 4 | ~2M |
| Medium | 512 | 8 | 8 | ~15M |
| Large | 1024 | 16 | 16 | ~100M |
Performance Tips
- Use mixed precision training for faster training on modern GPUs
- Adjust batch size based on your GPU memory
- Use gradient clipping for stable training
- Monitor validation loss to prevent overfitting
- Save checkpoints regularly to resume training
Dependencies
torch: PyTorch frameworktqdm: Progress barswandb: Experiment tracking (optional)sentencepiece: Tokenization (optional)
Contributing
- Fork the repository
- Create a feature branch
- Make your changes
- Add tests if applicable
- Submit a pull request
License
This project is for educational and research purposes. Please refer to the original LLaMA paper and Meta's licensing terms for commercial use.
References
Troubleshooting
Common Issues
- CUDA out of memory: Reduce batch size or use gradient accumulation
- Training instability: Use gradient clipping and learning rate scheduling
- Slow training: Enable mixed precision training with
--use_amp